GAN Computer Generate Art: A GANs Survey

Art has always been an essential component of human culture. Humans use art to express their imagination, thoughts, memories, and ideas. There are two categories of art: visual arts and performing arts. Visual arts consist of works that are painting, sculpture, and architecture. Performing arts consist of theater, film, music, and dance.
Early computer-generated art was very uniform and lifeless, unlike human arts. The computer would suggest possible suggestions, but a human has the final decision on accepting or rejecting the recommendation.
Recent advancements in Deep Learning (DL) allow a computer to create art without human supervision. This article will explore generative adversarial networks (GANs) and their applications in creating visual art, music, and literary text generation.
What are GANs?
Generative Adversarial Networks (GANs) is a deep learning architecture used for generative modeling. Generative modeling is a machine learning task that involves learning and extracting features from the input data. The model can generate new examples that could be generated based on the original dataset. GANs consist of two deep learning models, name generator and discriminator. The generator is trained to generate new data points from given noise. The discriminator identifies the data points to be either real or fake. The models are trained together in a zero-sum game with the end goal of the discriminator identifying fake images from the generator half the time. Figure 1. gives a general overview of the GAN architecture.

GANs Architectures
GAN generates new content based on min and max between the generator and discriminator. The generator attempts to create fake data similar to the data in the real dataset and continues to improve itself to trick the discriminator. The discriminator tries to classify the generated content as fake or real. The generator has no access to the real dataset and improves itself by minimizing the error feedback from the discriminator. The discriminator has access to the real dataset and improved by minimizing the error of predicting if the input is fake or real.
There are many different GANs architecture, but they build on the concept of generator and discriminator. Three different architectures have found success in generating art.
- Conditional GAN
- Deep Convolutional GAN (DCGAN)
- Recurrent Adversarial Networks
Conditional GAN
The conditional GAN expands on regular GAN by allowing the generator and discriminator to access auxiliary information such as class labels. The auxiliary information is combined with the noise input to allow the generator to generate data points based on a condition. Conditional GAN can be used to generate various genres of music such as jazz, rock, and classical.
Deep Convolutional GAN
In this architecture, the generator and the discriminator are made up of convolution networks (CNN). The convolution layers apply up sampling and down sampling to extract features from images. DCGAN has been successful in image and video classification, so this architecture would be perfect for image generation applications.
Recurrent Adversarial Networks
Recurrent Architectures are suitable for sequential or time-dependent data and used for text or audio generation. This architecture consists of two main components the encoder and decoder. The encoder extracts images of the current “canvas,” and the decoder decides whether to update the “canvas” or not by querying the dataset for the reference image.
Common Loss Functions
As mentioned, GAN training is based on a min-max game between the generator and the discriminator models. The models want to minimize the loss from their loss function. The generator minimized its loss by modifying the weight parameter for each epoch, generating realistic data points. The discriminator adjusts its weights so that it can distinguish between real and generated samples.
There are many loss functions; the following are generally used with GANs.
- Cross-Entropy Loss
- Binary Cross-Entropy Loss
- Mean Square Loss
- KL divergence Loss
- Wasserstein distance
Cross-Entropy Loss
Cross-Entropy loss is a standard loss function that used in DL.

p(x) is the true distribution and q(x) is the estimated distribution
Binary Cross-Entropy Loss
Binary Cross-Entropy loss is a variation of cross-entropy loss used specifically when dealing with two labels. The discriminator generally uses this loss function.

where p(yi) is the probability of belonging to the real class and 1 − p(yi) is the probability of belonging to the fake class.
Mean Square Error
Mean Square Error measures the average of the squares of the errors, the average squared difference between the estimated and actual values.

where yi is the actual value and y_hat_i is the predicted value for N training examples.
KL divergence
KL divergence calculates a score that measures the divergence of one probability distribution from another.

Where P(x) and Q(x) are the two distributions being compared.
Wasserstein Distance
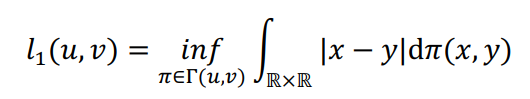
Where u and v are the distributions whose distance we are computing. Γ(u,v) is the set of distributions in ℝ × ℝ whose marginals are u and v on the first and second factors, respectively.
Visual Art Generation Using GANs
This section will provide an overview of current GANs used to generate art. GANs have been used to create cartoon images given a sketch using conditional GAN. The proposed architecture uses a supervised learning approach where the input is a black-and-white sketch, and the model generates a painted colorful image. The training dataset contains the pair of sketches as well as ground truth colored images. The generator was built using an encoder-decoder network. The discriminator consists of a decoder that classifies the sketch-image pair input as real or fake. This architecture was evaluated by asking volunteers to evaluate the created images against 3 different models and the new model outperformed the other models.
Another architecture allowed the user to specify a style based on the artist’s name or a style category. The generator utilizes a U-Net architecture, whereas the discriminator produces predictions of a style vector, sketch, and ‘real’ or ‘fake’ indicator using the input image sketch and the image produced by the generator. The images generated by this model were preferred about 63% of the time.
Using a modified version of DCGAN architecture, one researcher generated images that 53% more volunteers thought were real than DCGAN 35% believed were realistic. The discriminator was responsible for classifying whether the generated result was art or not and the art style. The generator takes input as random vectors and the feedback from the discriminator. The feedback consists of the discriminator’s prediction and style classification. Figure 2. Images generated by proposed DCGAN architecture

Table 1 provides a summary of all current techniques and architectures used to generate art.

Music and Melody Generation using GANs
Next, we will look at how GANs are used to generate music. Music data is stored in Musical Instrument Digital Interface (MIDI) files, which contain data to specify the musical instruction such as note’s notation, pitch, and vibrato.
Music generation required the computer to remember what notes were played before. In order to keep knowledge of previous notes an encoder is used to encode the previous frame into a corresponding latent representation, which the generator will refer to generate the next frame. The discriminator receives a real training frame as well as the synthesized one and both frames are compared to calculate the loss.
To handle the time-dependency of music, another proposed framework using GAN, consisting of a bi-directional LSTM generator and an LSTM discriminator. The dataset consists of XML files instead of MIDI. Furthermore, Bayesian optimization was selected to determine the parameters of the next sample by considering the distribution using Bayes’ theorem. This allowed the information to be extracted from previous sample points. The samples generated by the proposed model was likely to be detected as synthesized by human evaluators only 48.1% of the time.
Table 2 provides a summary of all current techniques and architectures used to generate music.

Poetry and Literary Text Generation using GANs
Most GAN architectures are restricted by several factors when it comes to text and sequential generation. For instance, the feedback given by the discriminator applies to the entire sequence, and the generations are usually continuous data.
One proposed architecture is SeqGAN addresses these challenges by creating a generator as stochastic policy in reinforcement learning (RL). The discriminator generates the reward for RL after it evaluates the entire sequence. Finally, passing the reward back to the intermediate state-action pairs using the Monte Carlo search algorithm.

The generated text is evaluated with a BLEU score that measures the similarity between the synthesized and human-created texts. When 70 experts on Chinese poems were asked to evaluate 20 real poems, 20 generated using maximum likelihood estimation, and 20 generated using SeqGAN. The SeqGAN poems outperformed the base maximum likelihood estimation model’s results. The SeqGAN outperformed the baseline with a 0.54 average score.
Another architecture generated Shakespearean prose given a painting. This architecture consists of CNN-RNN model as an agent and two discriminators. The architecture is depicted in figure 4. The poem generation used three parallel CNNs to extract the object, sentiment, and scene features. To generate the poetic elements, the features were combined with a skip-thought model. This is followed by a sequence-to-sequence model trained by policy gradient and two discriminators providing feedback rewards. Figure 5 is an example of what the model generated.


GANs are excellent at modeling continuous distributions, making them suitable for tasks like image generation. However, their application towards language modeling in discrete settings is limited due to the complexity of backpropagation through discrete random variables.
Table 3 is a summary of recent advancements in text generation with GANs.

Challenges
There are many challenges faced in the generation of visual arts, music arts, and literary arts. This section will break down some general challenges faced in each area.
Visual Arts
A major challenge in GANs training is the size of the datasets. Of all the image generation architecture, the smallest training dataset was 5000 images. In order to train novel applications, much time will be spent collecting the training dataset. This constraint can be a huge challenge for implementing projects.
Music Arts
There are several challenges with music generation. The most notable is that music is time-dependent, where generated notes are dependent on previously generated notes. The time-dependency add complexity to GANs architecture, where LSTM has been used to deal with this challenge.
Literary Arts
Literary Arts face many challenges with GANs architectures. Most research has been about poetry generation, and a clear conclusion about literary generation cannot be drawn. Before concluding, other literary applications would need to be explored, such as novel writing and rhyme generation.
A common challenge between all 3 arts is there no standard way to evaluate model performance. All the generated content has to be evaluated by humans and their evaluation is used to calculate the model’s performance.
Future Work
The following suggestions should be used to advance GANs ability to generate arts.
- Experiment with smaller datasets and GAN architectures for visual arts generation.
- Implement GANs to generate music in raw audio format, rather than MIDI file format.
- Implement longer text literary work generations including novels and dramas.
- Propose a well-defined and comprehensive qualitative validation for visual and performing arts.
Reference
To read more about generating computer art with GANs
GAN Computers Generate Arts? A Survey on Visual Arts, Music, and Literary Text Generation using Generative Adversarial Network
